Já não é de hoje que Python é tida como uma ótima linguagem para realizar tarefas de captura de dados na Internet. Eu sempre gostei de utilizar Python para capturar dados na Internet, mas nunca me preocupei em fazer isso de forma estruturada. No entanto, para um projeto pessoal, eu precisei recentemente realizar capturas de dados financeiros em diversos sites e senti a necessidade de alguma ferramenta que me permitisse fazer as capturas de forma mais estruturada. Eu sei que há diversos projetos que atacam este problema de diversas formas. Até investi algum tempo utilizando o Scrapy, mas logo vi que ele era demais para o que eu precisava. Fora que eu não encontrei, num primeiro momento, uma forma de fazer nele exatamente o que eu precisava (já explico). Foi assim que decidi fazer o meu próprio web scraper utilizando algumas coisas que eu já havia construído.
Por que você não usa o Scrapy?
Bem, não sei. Simplismente não gostei. Acho que tem dependências demais e não gosto de dependências demais. Já basta o Pandas, numpy, scipy e matplotlib que eu tenho que usar e ter uma vida miserável toda vez que eu decido compilar uma nova versão. Mas a verdade mesmo é que eu queria algo que pudesse executar no Google App Engine e com tamanha quantidade de dependências logo vi que não ia rolar.
Mas na verdade ainda, houveram alguns pontos que eu entendia relevantes e posto isso eu resolvi tentar uma solução caseira. Estes pontos são:
- Não gostei da forma que a classe
Itemfunciona. Na verdade gostei muito da classeItem, mas pra usar da maneira proposta eu me viro bem com umdict. - Outra coisa é que o método de parse é implementado de uma forma que toda a inteligência do scraper fica num lugar só.Eu procurava algo com uma idéia mais transcedental, de transformação, onde eu tivesse o conteúdo extraído da página e fosse transformando ele até obter o que eu desejasse.
- A declaração das URLs no spider pra mim era limitada, uma vez que eu precisava de URLs dinâmicas (com datas), pois alguns dados do mercado financeiro são divulgados assim, infelizmente!
Entra em cena: scraps
Bem, foi assim que eu começei, há alguns meses atrás, a escrever o scraps e desde então venho usando ele pra diversas capturas.
O scraps é um módulo Python muito simples onde eu tenho apenas 2 classes (Scrap e Attribute) e com elas eu resolvo a minha vida com capturas na Internet.
É óbvio que esta não é uma solução final, é um quebra galho mesmo, mas é um macaco gordo!
Coisas legais ao desenvolver scraps
- É muito bom desenvolver módulos para necessidades específicas. As vezes eu tenho a impressão que toda a programação (ou os programadores) querem tratar as soluções como grandes LEGOs e para isso ficam a busca de quais são os frameworks da moda para compor a obra. Obviamente para mim é fácil falar dado que não vivo de programação e não tenho a necessidade de mercado me pressionando para ficar na vanguarda. Na minha praia que é computação científica eu defendo menos bibliotecas e mais implementação.
- Eu pude finalmente utilizar Python Descriptors ou pelo mesmo usá-lo em algo útil que não um exemplo de descriptors. Fiquei muito feliz com o resultado final, apesar da implementação ainda parecer um hack malígno.
scraps em ação
A seguir vou mostrar um exemplo simples do meu uso para scraps, mas a idéia é bastante simples: capturar a taxa de juros de depósitos interbancários (Taxa DI) no site da CETIP.
A URL é da página incial da CETIP: http://www.cetip.com.br/ e segue o trecho de código HTML de onde quero capturar os dados:
...
<div class="box-taxa">
<p>
<strong><b>TAXA DI:</b></strong>
<span id="ctl00_Banner_lblTaxDateDI">(18/12/2014)</span>
</p>
<span class="bg-taxa"></span>
<p class="txt-taxa-porcentagem"><span id="ctl00_Banner_lblTaxDI">11,59%</span></p>
</div>
...
Segue também um pedaço da tela com uma visualização da informação:

Por sorte a CETIP utiliza id nas tags que me interessam, o que torna tudo mais simples.
Do trecho acima eu quero as tags span com ids ctl00_Banner_lblTaxDateDI e ctl00_Banner_lblTaxDI, com a data de divulgação da taxa e a taxa, respectivamente.
No mundo scraps eu tenho a classe scpras.Scrap que representa o que eu quero extrair do conteúdo da URL.
Nessa classe eu declaro atributros de classe que são instâncias da classe scraps.Attribute e identificam as tags que serão capturadas.
As tags são definidas pelo XPath que eu quero capturar.
Para o HTML acima temos:
class CetipScrap(scraps.Scrap):
data = scraps.Attribute(xpath='//*[@id="ctl00_Banner_lblTaxDateDI"]')
taxa = scraps.Attribute(xpath='//*[@id="ctl00_Banner_lblTaxDI"]')
Declarado dessa forma temos que o atributo data captura o conteúdo em texto de todas as tags com id ctl00_Banner_lblTaxDateDI e o atributo taxa o mesmo para o id ctl00_Banner_lblTaxDI.
Poderia ser mais específico com o XPath, no entanto, para este exemplo não faria diferença.
Em HTMLs menos estruturados vale a pena dedicar mais tempo a definição do XPath.
Para testar a captura é necessário apenas instanciar a classe CetipScrap e invocar o seu método fetch passando a URL.
scrap = CetipScrap()
scrap.fetch('http://www.cetip.com.br')
print(scrap.data)
print(scrap.taxa)
Este código gera:
['(18/12/2014)']
['11,59%']
Note que os atributos data e taxa retornam listas, da mesma forma que as APIs de XML sempre retornam listas de elementos nas suas consultas e o conteúdo das listas são textos contidos nas tags.
Dica: retorno dos atributos
Os atributos, instâncias de
scraps.Attribute, sempre retornam listas de textos.
Formatando os atributos
O trabalho poderia dar-se por encerrado aqui, afinal já consegui extrair os textos com a data de divulgação e o valor da taxa DI.
No entanto, eu ainda quero que estes dados sejam formatados.
Para trabalhar os dados eu tenho o atributo apply do construtor de scraps.Attribute onde eu passo uma coleção de funções que será aplicada a cada elemento da lista com o conteúdo em texto dos elementos.
Dessa maneira eu posso estruturar a transformação dos dados sem ficar preso a um método onde todo o trabalho de tratamento e transformação é realizado.
Para realizar essa tarefa eu crio algumas pequenas funções para me ajudarem e altero a declaração de CetipScrap, ficando tudo mais ou menos assim:
divide_by = lambda x: lambda y: y/x
def strptime(format='%Y-%m-%d'):
return lambda text: datetime.strptime(text, format)
def replace(_from, _to):
def _replace(text):
for f, t in zip(_from, _to):
text = text.replace(f, t)
return text
return _replace
class CetipScrap(scraps.Scrap):
data = scraps.Attribute(xpath='//*[@id="ctl00_Banner_lblTaxDateDI"]', apply=[
strptime('(%d/%m/%Y)')
])
taxa = scraps.Attribute(xpath='//*[@id="ctl00_Banner_lblTaxDI"]', apply=[
replace([',', '%'], ['.', '']), float, divide_by(100)
])
scrap = CetipScrap()
scrap.fetch('http://www.cetip.com.br')
print(scrap.data)
print(scrap.taxa)
A idéia aqui é:
- No atributo
dataformatar comodatetime.datetime - No atributo
taxaformatar comofloat, mas como o número está em pt-BT e em percentual, é necessário substituir vírgula por ponto e remover o símbolo de por cento, para na sequência converter para floar e dividir por 100
No atributo data a função strptime('(%d/%m/%Y)') é aplicada a cada elemento da lista.
Já no atributo taxa a funções replace([',', '%'], ['.', '']), float e divide_by(100) são aplicadas na ordem espeficidada, a cada elemento da lista.
Executando o código acima temos:
[datetime.datetime(2014, 12, 18, 0, 0)]
[0.1159]
As funções strptime, replace e divide_by me ajudaram na transformação dos dados.
Estas funções retornam funções que executam as tarefas para as quais foram especificadas.
Por exemplo, a chamada divide_by(100) retorna uma função que divide o argumento por 100 e a chamada strptime('(%/d/%m/%Y)') retorna uma função que recebe uma argumento texto, no formato especificado, e retorna um datetime.datetime.
Uma abordagem interessante para o uso de scraps seria investir mais tempo na criação dessas funções, para assim tornar a transformação em um conjunto de regras padrão.
Funcionaria mais ou menos como no diagrama abaixo.
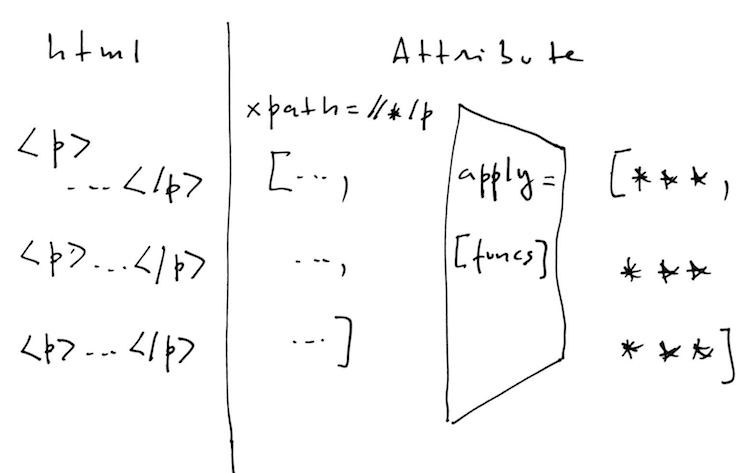
Abaixo segue o código final da implementação onde eu utilizo scraps para obter a taxa de juros diária divulgada no site da CETIP.
Conclusão
Escrever scpras foi divertido e usá-lo é mais legal ainda.
Exercito muito a minha criatividade pensando em transformações para os dados.
Mas há uma ideia subliminar aqui que é estruturar do tratamento dos dados em pequenas etapas.
Uma vez que eu consiga mapear um conjunto de funções que atende a um número considerável de problemas eu posso estruturar essa solução e torná-la mais automática, o que me faz pensar na construção de capturas on-line.
De qualquer forma, scraps é um módulo que eu classificaria como quick-and-dirty, mas me ajuda a exercitar a minha criatividade e a dar vazão as coisas.