Eu gosto de praticar corrida de rua, e 2014 foi um ano fenomenal pois eu levei isso para o próximo nível, comecei a praticar meias maratonas. Em 2014 foram 4 começando com a Meia Maratona de SP em março e terminando com o Circuito Athenas em novembro.

A primeira primeira prova do ano, em março, foi terrível pois, estava o calor estava muito forte. Concluí a prova em 2h02m com muito sacrifício. Nas 3 provas seguintes eu fiz as marcas 1h48m, 1h49m, 1h47m, ou seja, consegui reduzir o meu tempo em 15m aproximadamente. Obviamente a experiência da primeira prova serviu para as demais, além do treinamento, mas todas as demais provas foram em dias de temperaturas mais amenas. Uma ponto muito discutido pelos praticantes de corrida de rua é o efeito da temperatura no desempenho do atleta, principalmente para os amadores. No treinamento é perceptível, dias mais quentes são miseráveis para treinar—e dias mais frios miseráveis para acordar. O calor faz com que a bateria do atleta descarregue mais rapidamente e não é apenas uma questão de recarregar a bateria, se hidratando e consumindo carboidratos e sal, o corpo vai meio que se estafando produzindo caimbras e podendo acontecer até coisa pior, como desmaiar por carência de alguma coisa.
Com isso em mente eu resolvi buscar formas quantitativas de avaliar o desempenho de corredores versus o clima. Procurei algumas corridas no Brasil e a mais tradicional é a Corrida Internacional de São Silvestre que ocorre sempre no mesmo dia do ano, apesar de ter ocorrido em horários diferentes ao longo dos anos. A corrida de São Silvestre tem o percurso de 15Km, é menor que uma meia maratona, 21Km, no entanto, em 15Km os efeitos do clima já se tornam perceptíveis. Um aspecto favorável a Corrida de São Silvestre é que ela ocorre no mesmo dia do ano, 31 de dezembro, e isso ajuda a cruzar com os dados de clima, que podem vir em frequência diária. Outro ponto é que no site da corrida temos a área de campeões com os tempos de todos os campeões desde a primeira edição em 1925. Observando apenas os dados dos campeões a análise fica um pouco viesada, pois aqui eu assumo a hipótese de que os campeões tenham mais resistência que atletas não profissionais e talvez eu não consiga medir o que eu desejo, que é o efeito do clima sobre o desempenho da corrida. Portanto, o não resultado é um resultado, indicando que a amostra deve ser estendida.
Neste post eu vou apresentar como eu capturei os dados dos campeões e os dados de clima. A análise fica para outro post. Como toda a análise ficou maior do que esperava eu criei o repositório saosilvestre para todos os códigos, tanto da captura como da análise. Toda a captura dos dados foi feita com Python e a análise feita com R. Este trabalho foi uma ótima oportunidade para ver como essas linguagens se complementam. Claro que tudo poderia ser realizado apenas com uma linguagem, mas eu tenho pontos fortes e fracos em ambas e neste caso resolvi utilizar os pontos que considero fortes. Eu já tinha um material para fazer capturas em Python pronto e fazer a análise de dados com R foi muito simples.
Capturando os dados dos campeões da Corrida de São Silvestre
Como já mencionei a captura foi feita com Python e em particular utilizei o módulo scraps desenvolvido por mim. Além do scraps utilizei outros 2 módulos também desenvolvidos por mim: textparser e tinydf. Já falei a respeito do scraps no post Faça você mesmo um Web Scraper em Python. O textparser faz, como o nome sugere, parse de texto e faz isso basendo-se em expressões regulares, nada mais trivial. A motivação para criá-lo foi que toda vez que eu precisava converter um texto para um número ou data eu ficava copiando funções de um lado para outro e foi então que decidi colocar tudo em um lugar só e que fosse útil de forma simples e direta. O que torna-o interessante é que as expressões regulares são declaradas na documantação dos métodos e os métodos são preparados para receber o texto e o objeto re.MatchObject que traz informações do parse. O uso do textparser merece um post, aqui, por hora, vou me ater a implementação pois acredito que a simplicidade vai facilitar a compreensão. O tinydf é uma implementação rudimentar de um DataFrame. Digo rudimentar por que se eu quisesse um DataFrame de verdade seria melhor usar o pandas, no entanto, eu preciso do DataFrame para gerar o arquivo CSV, por isso criei o tinydf para gerar dados tabulares em formatos comuns: CSV, JSON, e dict, por enquanto.
A captura é executada em 3 etapas:
- Definição do scrap para parse do html
- Criação do parser de texto para a extração e formatação do conteúdo de interesse
- Formatação em CSV
Definindo o scrap
O scrap é fundamental pois ele determina como o conteúdo da página vai ser capturado de fato, após a captura realizada pelo scrap é massagem nos dados para que fiquem em um formato interesante para a análise. Os campeões estão dividos em décadas e em cada década eles são distribuídos em DIVs como este:
<div class="col-lg-6 col-sm-6 col-xs-12">
<h2>Edwin Kipsang</h2>
<h4>89ª Corrida de São Silvestre – 2013</h4>
<p>Naturalidade: Quênia<br>
Equipe: -<br>
Horário da Largada: 09h00<br>
Tempo: 43min47<br>
Percurso: 15 Km</p>
<p><strong>Percurso</strong><br>
Largada: Av. Paulista, próximo à Rua Ministro Rocha Azevedo (sentido Consolação).<br>
Chegada: Av. Paulista, 900, em frente ao Edifício da Fundação Cásper Líbero.</p>
<hr>
</div>
Acesse uma página de campeões completa no link.
Os elementos de interesse são os títulos h2 e h4, e os parágrafos.
Para capturar dados com esta estrutura eu criei o seguinte scrap.
split = lambda sep=None, maxsplit=-1: lambda s: str.split(s, sep=sep, maxsplit=maxsplit)
foreach = lambda func: lambda seq: [func(x) for x in seq]
class SaoSilvestreScrap(scraps.Scrap):
names = scraps.Attribute(xpath='//*[@id="content"]/div/div/div/div/div/h2')
races = scraps.Attribute(xpath='//*[@id="content"]/div/div/div/div/div/h4')
info1 = scraps.Attribute(xpath='//*[@id="content"]/div/div/div/div/div/p[1]', apply=[
split(sep='\n'), foreach(str.strip)
])
info2 = scraps.Attribute(xpath='//*[@id="content"]/div/div/div/div/div/p[2]', apply=[
split(sep='\n'), foreach(str.strip)
])
O scrap tem 3 atributos: names com os nomes dos campeões, races com os anos e os números das corridas, info1 com informações do campeão como país, tempo da prova, horário de largada e percurso, e info2 com informações da prova como pontos de largada e chegada.
Dessa dorma temos 1 informação no atributo names, 2 informações no atributo races, 4 informações em info1 e 2 em info2, totalizando 9 informações que vão virar 9 colunas em um DataFrame.
Os atributos info1 e info2 são parágrafos de forma que foi necessário quebrá-los em linhas e limpar as bordas antes de usá-los.
Aqui eu tenho um ponto importante, eu poderia ter feiro todo o parse já no scrap, mas preferi deixar isso para uma segunda etapa. Essa foi uma decisão subjetiva, gosto de separar o problema em partes pequenas.
O que eu espero após SaoSilvestreScrap ser aplicado a uma página de campeão?
Eu espero que names contenha uma lista todos os nomes dos campeões contidos na página, races contenha outra lista com todos os títulos com os números das provas e seus respectivos anos, info1 contenha uma lista de listas pois, originalmente eu teria uma lista com os conteúdos dos parágrafos e após o split ser aplicado a cada elemento eu fico com uma lista de listas, e em info2 também espero uma lista de listas, pelo mesmo motivo de info1.
Extraindo informação do texto
O scrap me dá a informação bruta e eu preciso trabalhar essa informação, convertendo para os formatos padronizados e associar aos campos já identificados:
- nome
- país
- corrida
- ano
- horário
- tempo
- percurso
- largada
- chegada
Para extrair a informação que eu quero do texto eu criei uma subclasse de textparser.TextParser.
class SaoSilvestreParser(textparser.TextParser):
def parseNaturalidade(self, text, match):
r'^Naturalidade:\s(.+)\s?$'
return ('pais', match.group(1))
def parseHorarioLargada(self, text, match):
r'^Horário da Largada:\s(\d?\d)h(\d\d)\s?$'
return ('horario', '{0}:{1}:00'.format(match.group(1), match.group(2)))
def parseHorarioLargada2(self, text, match):
r'^Horário da Largada:\s(\d+) horas'
return ('horario', '{0}:00:00'.format(match.group(1)))
def parseTempo(self, text, match):
r'^Tempo\s?:\s?(\d\d)m(in)?(\d\d)s?'
return ('tempo', '00:{0}:{1}.000'.format(match.group(1), match.group(3)))
def parsePercurso(self, text, match):
r'^Percurso:.*\s(\d+(\.\d+)?)\s?([Kk]?)m\s?$'
return ('percurso', eval(match.group(1).replace('.', '')) * (1000 if match.group(3).lower() == 'k' else 1))
def parseParticipantes(self, text, match):
r'^Participantes:\s(\d+\.\d+)\satletas\.\s?$'
return ('participantes', eval(match.group(1).replace('.', '')))
def parseLargada(self, text, match):
r'Largada:\s(.+)\.?\s?$'
return ('largada', match.group(1))
def parseChegada(self, text, match):
r'Chegada:\s(.+)\.?\s?$'
return ('chegada', match.group(1))
def parseRace(self, text, match):
r'^(\d+). Corrida de São Silvestre – (\d\d\d\d)a?$'
return [('corrida', eval(match.group(1))), ('ano', eval(match.group(2)))]
def parseText(self, text):
return None
Note que cada método possui uma expressão regular como documentação, exceto parseText que é o retorno padrão quando nenhum outro método é chamado.
O retorno de cada método é uma tupla, ou uma lista de tuplas no caso de parseRace, onde o primeiro elemento da tupla identifica o campo e o segundo elemento o seu valor.
Essa foi a forma que eu encontrei para fazer o parse por que eu preciso da identidicação dos campos para colocá-los em uma estrutura tabular.
O textparser.TextParser possui um método parse(text) onde o texto passado como argumento é testado para cada expressão regular, a primeira que der match o respectivo método é chamado.
Caso não ocorra um match o método retorna o padrão, que é executar parseText.
A idéia aqui é passar os atributos races, info1 e info2 por parse e assim extrair a informação que me interessa.
No entanto, temos listas e listas de listas e parse deve ser aplicado para cada elemento atômico.
Por isso eu criei uma composição de funções que aplica parse a cada elemento atômico e remove os valores nulos, que não deram match.
def compose(*functions):
f = list(functions)
f.reverse()
return reduce(lambda f, g: lambda x: f(g(x)), f)
parser = SaoSilvestreParser()
parse_and_filter_false = compose(partial(map, parser.parse), partial(filter, lambda x: x is not None), list)
infos1 = [parse_and_filter_false(x) for x in scrap.info1]
infos2 = [parse_and_filter_false(x) for x in scrap.info2]
races = parse_and_filter_false(scrap.races)
A função parse_and_filter_false recebe uma lista e aplica parse para cada elemento, em seguida remove os nulos e no fim gera uma lista, dado que Python3 retorna geradores (para as funções map e filter).
Após o parsing eu tenho diversas tuplas com os campos definidos. Agora veremos como juntar estes campos em uma estrutura tabular.
Formatando dados em CSV
Para juntar tudo em uma estrutura tabular antes eu preciso que todos os campos sigam o mesmo modelo, ou seja, preciso de tuplas com pares (nome, valor) de cada campo.
Como vimos anteriormente, races, info1 e info2 foram gerados neste modelo, mas names não.
Para resolver isso eu criei a função keyfy
keyfy = lambda seq, key: list(map(lambda x: [(key, x)], seq))
que gera tuplas identificadas com os elementos de uma sequencia.
O código abaixo mostra como utilizo tinydf.DataFrame para juntar todos os dados.
ds = tinydf.DataFrame()
ds.headers = ['nome', 'pais', 'corrida', 'ano', 'horario', 'tempo', 'percurso', 'largada', 'chegada']
names = keyfy(scrap.names, 'nome')
rows = [dict(info1 + info2 + race + name) for info1, info2, race, name in zip(infos1, infos2, races, names)]
for row in rows:
ds.add(**row)
print(ds.csv)
Note que gero um dict a partir de um zip onde compacto todos os campos.
Os dicionários são adicionados ao DataFrame para que no fim o CSV seja impresso.
tinydf também possui atributos json e dict, simplificando a geração de dados estruturados em diferentes formatos.
Resultado
O resultado final é um arquivo CSV com todos os campeões e todos os campos listados anteriormente. Este arquivo for gerado e pode ser baixado direto do link.
Este arquivo contem diversos erros: campos com valores faltantes (missing values), informações trocadas, entre outros. Estes erros são consequência da má qualidade dos dados e do fato de não haver uma forma estrutrada de armazená-los. Vou analizar os dados capturados em outro post e neste momento vou detalhar melhor o tratamento dos dados. Vou também analizar a evolução dos tempos de corrida e relacionar com a temperatura, com o objetivo de identificar se a temperatura afeta o desempenho dos campeões.
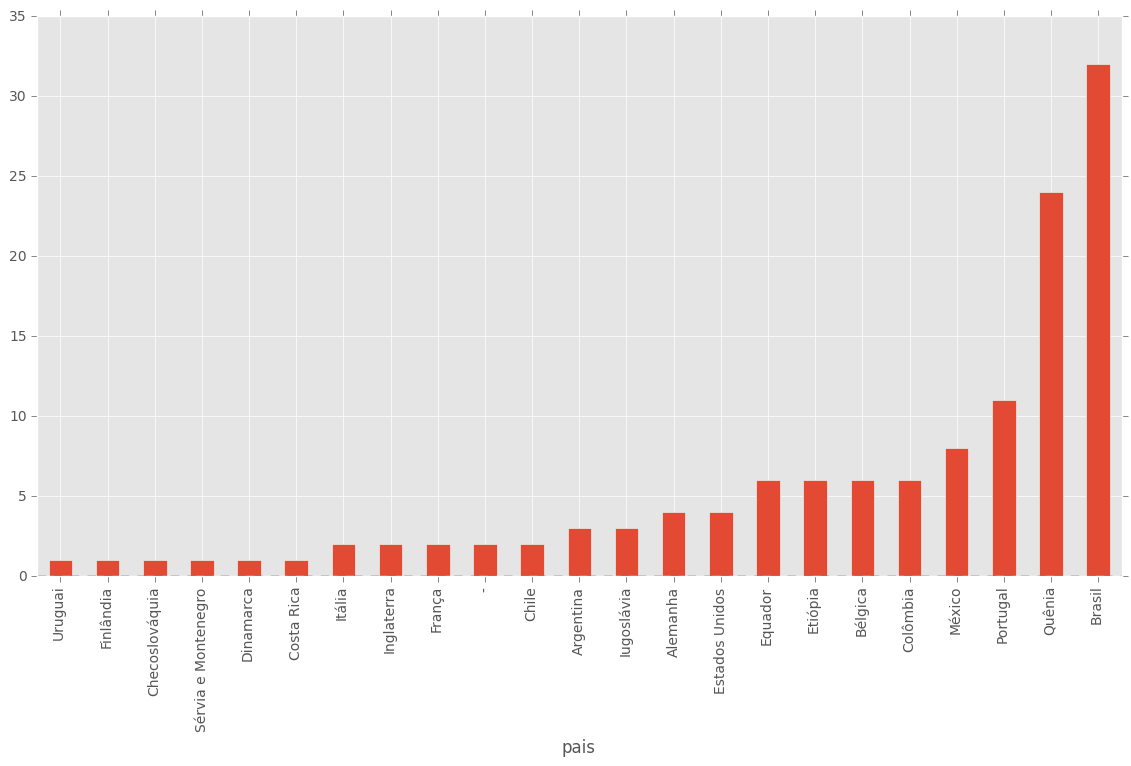
Por hora eu gerei um gráfico com a contagem de campeões por paises.
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('ggplot')
ss = pd.read_csv("https://raw.githubusercontent.com/wilsonfreitas/saosilvestre/master/saosilvestre.csv")
ss_pais = ss.groupby('pais')
ss_pais.corrida.count().sort(inplace=False).plot(kind='bar', figsize=(14,7))
Código final
Segue o código final como é executado.
Ao longo do texto eu acabei simplificando algumas chamadas com a intenção de tornar o texto mais didático. Esse foi um trabalho interessante em que após tê-lo concluído eu achei que ficou simples, mas tendo que colocar em texto eu vi que ficou um pouco grande, maior do que eu esperava.