No post Captura de dados da Corrida de São Silvestre com Python—Parte 1 eu levanto uma questão: Como o clima influencia o desempenho dos corredores de rua? Nesse post eu apresento como os dados dos campeões da corrida de São Silvestre foram capturados do site da corrida utilizando Python e em seguida transformados em um arquivos CSV.
Agora vou mostrar como o arquivo CSV foi utilizado, como os dados foram limpos e como foram formatados para que eu tenha os tipos corretos para a análise dos dados. Neste post eu uso R ao invés de Python, sem nenhuma razão específica.
Montando o ambiente
Para fazer esta análise eu carreguei os seguintes pacotes:
library(ggplot2)
library(dplyr)
library(tidyr)
library(lubridate)
O ggplot2 é para fazer gráficos, dplyr e tidyr para tratar os datasets e lubridate para manipulação de data e hora.
Pessoalmente acho o dplyr excepcional para o manejo com os dados, ele impõe uma forma fluida de pensar nas colunas do dataset como variáveis e a partir daí todo o processo de manipulação de dados se torna simples.
Carregando os dados
Vamos começar carregando o arquivo saosilvestre.csv.
library(RCurl)
csv_file <- getURL('https://raw.githubusercontent.com/wilsonfreitas/saosilvestre/master/saosilvestre.csv')
ss <- read.csv(text=csv_file, header=TRUE, stringsAsFactor=FALSE)
head(ss)
## nome pais corrida ano horario tempo
## 1 Dawit Admasu Eti<U+00F3>pia 90 2014 09:00:00 00:45:04.000
## 2 Ymer Wude Ayalew Eti<U+00F3>pia 90 2013 08:40:00 00:50:43.000
## 3 Edwin Kipsang Qu<U+00EA>nia 89 2013 09:00:00 00:43:47.000
## 4 Nancy Kipron Qu<U+00EA>nia 89 2013 08:40:00 00:51:58.000
## 5 Edwin Kipsang Qu<U+00EA>nia 88 2012 09:00:00 00:44:05.000
## 6 Maurine Kipchumba Qu<U+00EA>nia 88 2012 08:40:00 00:51:42.000
## percurso
## 1 15000
## 2 15000
## 3 15000
## 4 15000
## 5 15000
## 6 15000
## largada
## 1 Av. Paulista, pr<U+00F3>ximo <U+00E0> Rua Ministro Rocha Azevedo (sentido Consola<U+00E7><U+00E3>o).
## 2 Av. Paulista, pr<U+00F3>ximo <U+00E0> Rua Ministro Rocha Azevedo (sentido Consola<U+00E7><U+00E3>o).
## 3 Av. Paulista, pr<U+00F3>ximo <U+00E0> Rua Ministro Rocha Azevedo (sentido Consola<U+00E7><U+00E3>o).
## 4 Av. Paulista, pr<U+00F3>ximo <U+00E0> Rua Ministro Rocha Azevedo (sentido Consola<U+00E7><U+00E3>o).
## 5 Av. Paulista, pr<U+00F3>ximo <U+00E0> Rua Frei Caneca.
## 6 Av. Paulista, pr<U+00F3>ximo <U+00E0> Rua Frei Caneca.
## chegada
## 1 Av. Paulista, 900, em frente ao Edif<U+00ED>cio da Funda<U+00E7><U+00E3>o C<U+00E1>sper L<U+00ED>bero.
## 2 Av. Paulista, 900, em frente ao Edif<U+00ED>cio da Funda<U+00E7><U+00E3>o C<U+00E1>sper L<U+00ED>bero.
## 3 Av. Paulista, 900, em frente ao Edif<U+00ED>cio da Funda<U+00E7><U+00E3>o C<U+00E1>sper L<U+00ED>bero.
## 4 Av. Paulista, 900, em frente ao Edif<U+00ED>cio da Funda<U+00E7><U+00E3>o C<U+00E1>sper L<U+00ED>bero.
## 5 Av. Paulista, 900, em frente ao Edif<U+00ED>cio da Funda<U+00E7><U+00E3>o C<U+00E1>sper L<U+00ED>bero.
## 6 Av. Paulista, 900, em frente ao Edif<U+00ED>cio da Funda<U+00E7><U+00E3>o C<U+00E1>sper L<U+00ED>bero.
Eu não vou utilizar as colunas largada, chegada e horario e como elas poluem a vizualização do dataset eu decidi removê-las:
ss <- ss %>% select(-largada, -chegada, -horario)
head(ss)
## nome pais corrida ano tempo percurso
## 1 Dawit Admasu Eti<U+00F3>pia 90 2014 00:45:04.000 15000
## 2 Ymer Wude Ayalew Eti<U+00F3>pia 90 2013 00:50:43.000 15000
## 3 Edwin Kipsang Qu<U+00EA>nia 89 2013 00:43:47.000 15000
## 4 Nancy Kipron Qu<U+00EA>nia 89 2013 00:51:58.000 15000
## 5 Edwin Kipsang Qu<U+00EA>nia 88 2012 00:44:05.000 15000
## 6 Maurine Kipchumba Qu<U+00EA>nia 88 2012 00:51:42.000 15000
Muito melhor!
Importante: o operador
%>%é um pipe e compõe as sucessivas chamadas de funções para transformações em um dataset. O retorno da primeira expressão é atribuído ao primeiro argumento da função na segunda expressão, e caso houvessem mais expressões esse comportamento se repetiria até encontrar a última expressão e retornar o seu resultado para o chamador. Este operador, que é extensamente utilizado em conjunto com as funções dodplyr, tem origem no pacotemagrittr.
Limpando e formatando os dados
Para ter o dataset pronto para uso eu preciso formatar os dados e corrigir os erros. No processo de análise eu encontrei alguns erros e como não será possível reproduzir este processo aqui eu vou listar os erros e apresentar as soluções.
Corrigindo o ano
O ano da corrida número 90 está errado.
Este erro pode ser observado olhando os dados, veja na listagem abaixo onde eu uso a função filter do dplyr para selecionar os registros em que a coluna corrida é 90.
ss %>% filter(corrida == 90)
## nome pais corrida ano tempo percurso
## 1 Dawit Admasu Eti<U+00F3>pia 90 2014 00:45:04.000 15000
## 2 Ymer Wude Ayalew Eti<U+00F3>pia 90 2013 00:50:43.000 15000
Para corrigir isso é necessário definir para 2014 o ano dos registros que possuem corrida igual a 90.
ss <- ss %>% mutate(ano=ifelse(corrida == 90, 2014, ano))
Apenas para ter certeza vamos verificar os dados após a correção.
## nome pais corrida ano tempo percurso
## 1 Dawit Admasu Eti<U+00F3>pia 90 2014 00:45:04.000 15000
## 2 Ymer Wude Ayalew Eti<U+00F3>pia 90 2014 00:50:43.000 15000
Ótimo, ano corrigido!
Corrigindo o pais
Na coluna pais há registros mau preenchidos, alguns registros estão preenchidos errados e também há registros vazios.
Vou começar com os registros errados, eles estão preenchidos com um hífen - e devem ser substituídos pelos países corretos.
ss %>% filter(pais == '-')
## nome pais corrida ano tempo percurso
## 1 Marizete de Paula Rezende - 78 2002 00:54:02.000 15000
## 2 Lydia Cheromei - 76 2000 00:50:33.000 15000
O pais do primeiro registro é Brasil e para o segundo é Quênia.
Para corrigir esse erro eu utilizo a função grep para identificar os registros errados e substituir a coluna pais pelos valores comentados, mas mantendo a ordem correta, que eu consigo saber observando a listagem acima.
idx <- grep('^-', ss$pais)
ss[idx[1], 'pais'] <- 'Brasil'
ss[idx[2], 'pais'] <- 'Quênia'
Há também um registro com pais vazio.
ss %>% filter(pais == '')
## nome pais corrida ano tempo percurso
## 1 Alfredo Gomes 1 1925 00:23:10.000 6200
O pais para este registro é Brasil e como é apenas 1 fica fácil corrigir com dplyr::mutate.
ss <- ss %>% mutate(pais=ifelse(pais == '', 'Brasil', pais))
Pronto, pais corrigido.
Corrigindo o percurso
Há 1 registro com erro na coluna percurso, e esse foi tricky para descobrir.
Fazendo o gráfico de percurso por ano posso observar que a partir da década de 90 os percursos se mantém constantes em 15 km.
ggplot(data=ss, aes(x=ano, y=percurso)) + geom_point(size=2) + geom_line()
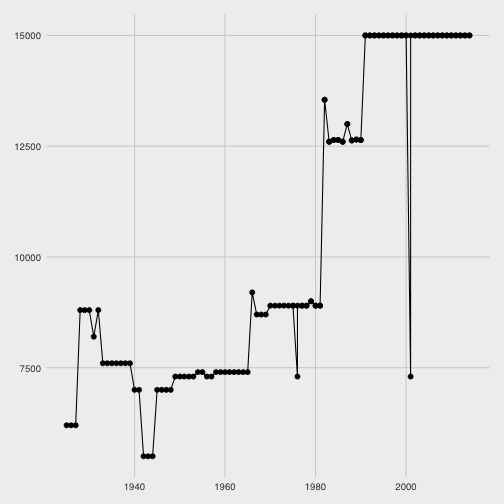
Entretanto, logo após o ano 2000 há um ponto que caí vertiginosamente de 15 km para aproximadamente a metade.
Observando o gráfico vejo que há variações semelhantes, porém isso pode me levar a questionar os demais valores.
Por isso eu somente consegui identificar este erro quando criei a variável pace que mede a quantidade de tempo que um corredor leva para percorrer 1 km.
Eu converto a variável tempo que é um character para difftime que é um objeto que representa intervalos de tempo.
Pessoalmente acho difftime um nome miserável de ruim, mas no R algumas coisas são assim mesmo, meio feias ;).
Depois dessa conversão eu consigo fazer as operações aritiméticas com difftime necessárias para o cálculo do pace.
ss <- ss %>% mutate(tempo=as.difftime(tempo), pace=1000*tempo/percurso)
Fazendo o gráfico do pace dos campeões por corrida temos:
ggplot(data=ss, aes(x=ano, y=as.numeric(pace))) + geom_point(size=2) + geom_line()
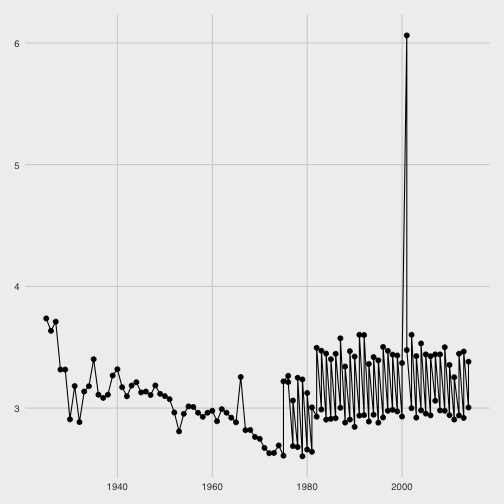
Bingo! É possível notar que no mesmo ano que no gráfico anterior há um outliar.
Os paces de campeões são abaixo de 4 min/km, em média, de forma que um pace de 6 min/km é implausível.
Para corrigir este registro vou assumir que ele é 15 km, como os demais em anos próximos.
Dessa forma, será necessário atualizar o percurso e calcular novamente o pace.
Para corrigir o percurso vou utilizar as operações de indexação no data.frame junto com a função which e para recalcular o pace eu utilizo a mesma expressão de antes (com mutate).
ss[which(ss$pace > 4),]$percurso <- 15000
ss <- ss %>% mutate(pace=1000*tempo/percurso)
Gerando novamente o gráfico dos paces observo que o erro está corrigido.
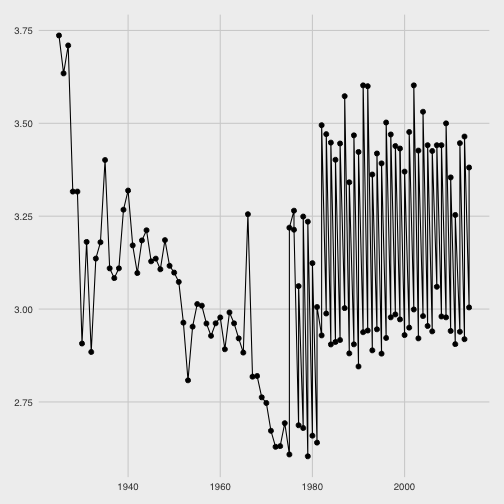
Importante: é necessário converter o
pace, que é umdifftime, paranumericpara construir o gráfico com ggplot2.Importante: notei no gráfico dos paces que nos anos recentes há dois níveis distintos de pace. Isso refere-se aos paces masculino e feminino que vamos classificar em breve.
Classificando masculino e feminino: criando sexo
Como observei nos gráficos de pace, há uma diferença entre os paces: masculino e feminino, de forma que é interessante que eu consiga classificar os corredores quanto ao sexo. Eu sei que o tempo masculino é menor que o feminino, ou seja, um campeão do sexo masculino percorre a distância da prova em menos tempo do que uma campeã. Então eu posso assumir que nos anos em que há apenas 1 ocorrência, o sexo do campeão é masculino, e quando houverem 2 ocorrências o menor pace é do sexo masculino e o maior é do feminino. Também estou assumindo que não há provas com mais de 2 gêneros. Bem, posto isso a estratégia para classificar os campeões pelo sexo é:
- ordenar por
anoetempo - agrupar por
ano - criar a variável
sexoconsiderando sexo masculino quando a contagem do grupo for 1 e (masculino, feminino), nesta ordem, quando a contagem do grupo for diferente de 1
Parece meio confuso mas com dplyr isso tudo pode ser resolvido em meia dúzia de linhas.
ss <- ss %>%
arrange(ano, tempo) %>%
group_by(ano) %>%
mutate(sexo=if (n() == 1) 'masculino' else c('masculino', 'feminino')) %>%
ungroup %>%
as.data.frame
tail(ss)
## nome pais corrida ano tempo
## 125 Edwin Kipsang Qu<U+00EA>nia 88 2012 44.08333333 mins
## 126 Maurine Kipchumba Qu<U+00EA>nia 88 2012 51.70000000 mins
## 127 Edwin Kipsang Qu<U+00EA>nia 89 2013 43.78333333 mins
## 128 Nancy Kipron Qu<U+00EA>nia 89 2013 51.96666667 mins
## 129 Dawit Admasu Eti<U+00F3>pia 90 2014 45.06666667 mins
## 130 Ymer Wude Ayalew Eti<U+00F3>pia 90 2014 50.71666667 mins
## percurso pace sexo
## 125 15000 2.938888889 mins masculino
## 126 15000 3.446666667 mins feminino
## 127 15000 2.918888889 mins masculino
## 128 15000 3.464444444 mins feminino
## 129 15000 3.004444444 mins masculino
## 130 15000 3.381111111 mins feminino
Eu executo um tail para apresentar os resultados porque os dados foram ordenados por ano e portanto os últimos registros são os que apresentam provas com os 2 sexos.
Para verificar se a classificação está correta vou fazer um gráfico do tempo por ano agrupando por sexo para ilustrar a classificação dos campeões.
Mas antes vou criar mais uma coluna chamada contagem, com a contagem de ocorrências da corrida, essa variável me ajuda a filtar os resultados para apresentar apenas as corridas em que houveram 2 campeões, pois dessa forma eu consigo comparar os níveis de pace por sexo.
ss <- ss %>%
group_by(ano) %>%
mutate(contagem=n()) %>%
ungroup %>%
as.data.frame
ggplot(data=subset(ss, contagem == 2),
aes(x=ano, y=as.numeric(tempo), group=sexo, colour=sexo)) +
geom_point(size=2)
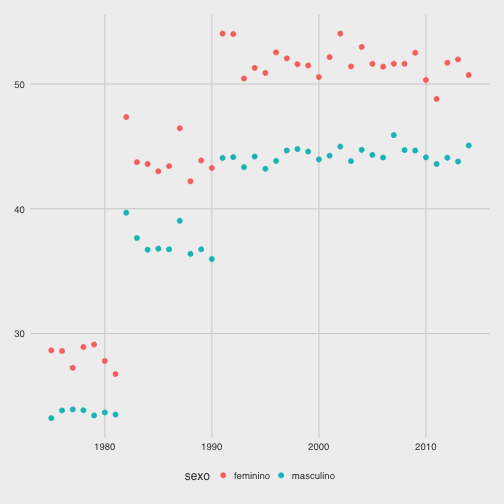
Este gráfico me intriga porque a é possível observar 3 níveis distintos para o comportamento dos tempos dos campeões. Isso é um reflexo do percurso da prova, pois o tamanho do percurso aumentou ao longo dos anos até estacionar em 15 km. Outro gráfico semelhante ao anterior, mas apresentando percurso por ano agrupando por sexo, pode mostrar isso melhor.
ggplot(data=subset(ss, contagem == 2),
aes(x=ano, y=percurso, group=sexo, colour=sexo)) +
geom_point(size=2)
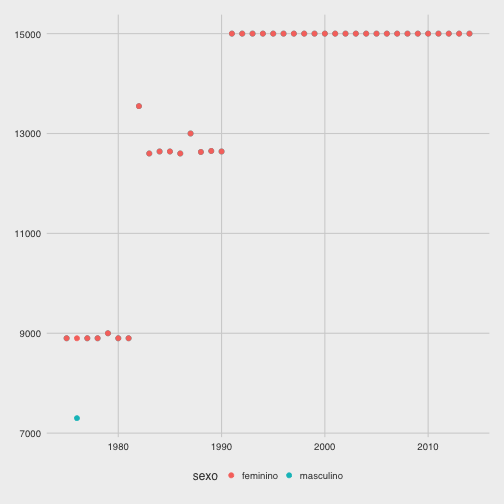
Em todos as provas, exceto na segunda ocorrência do gráfico acima, os percursos masculinos e femininos são iguais. Este é um forte indício de que o percurso dessa prova para o sexo feminino também está errado.
head(subset(ss, contagem == 2))
## nome pais corrida ano tempo
## 51 Victor Mora Col<U+00F4>mbia 51 1975 23.21666667 mins
## 52 Christa Valensieck Alemanha 51 1975 28.65000000 mins
## 53 Edmundo Warnke Chile 52 1976 23.83333333 mins
## 54 Christa Valensieck Alemanha 52 1976 28.60000000 mins
## 55 Domingo Tibaduiza Col<U+00F4>mbia 53 1977 23.91666667 mins
## 56 Loa Olafsson Dinamarca 53 1977 27.25000000 mins
## percurso pace sexo contagem
## 51 8900 2.608614232 mins masculino 2
## 52 8900 3.219101124 mins feminino 2
## 53 7300 3.264840183 mins masculino 2
## 54 8900 3.213483146 mins feminino 2
## 55 8900 2.687265918 mins masculino 2
## 56 8900 3.061797753 mins feminino 2
Listando o dataset observo que os registros da corrida 52 possuem os diferentes percursos, dessa forma vou assumir que os 2 deveriam ser 8900 m.
Identificado o problema vou seguir com a mesma solução, selecionar os registros da corrida 52 e definir o percurso para 8900 m.
ss[which(ss$corrida == 52),]$percurso <- 8900
ss <- ss %>% mutate(pace=1000*tempo/percurso)
Para encerrar as dúvidas vou empilhar os gráficos de pace e tempo por ano, para avaliar se as hipóteses assumidas são pertinentes.
library(gridExtra)
ss_mw <- subset(ss, contagem == 2)
plot_pace <- ggplot(data=ss_mw, aes(x=ano, y=as.numeric(pace), group=sexo, colour=sexo)) +
geom_point(size=2)
plot_time <- ggplot(data=ss_mw, aes(x=ano, y=as.numeric(tempo), group=sexo, colour=sexo)) +
geom_point(size=2)
grid.arrange(plot_pace, plot_time, nrow=2)
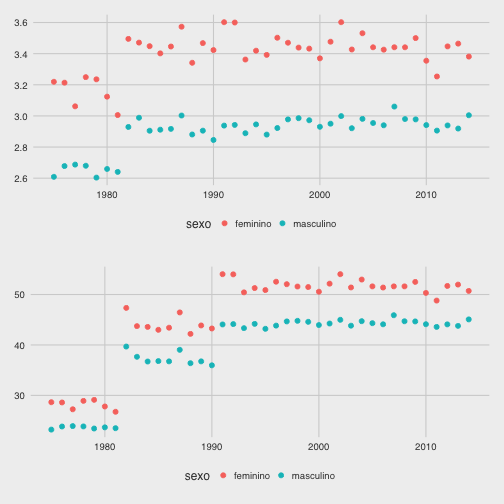
Neste gráfico observo 2 regimes de pace contra 3 regimes de tempo. Há 3 regimes de tempo porque o tempo é diretamente proporcional ao percurso, maior o percurso, maior o tempo, e no período avaliado temos 3 percursos: 8900 m, 13 km e 15 km. Por outro lado os 2 regimes de pace são curiosos pois indicam a relação do pace com o tamanho do percurso, ou seja, maior o percurso, maior o pace, o que é esperado, dado que é difícil para um corredor manter o mesmo nível de esforço em provas de diferentes distância. No entanto, a diferença de 2 km entre os percursos de 13 km e 15 km não influencia o pace dos campeões.
Outra coisa, estes gráficos me fazem desconfiar de que a diferença do desempenho entre os sexos se mantém constante, em média, indicando algum tipo de estacionariedade, mas ainda seriam necessários mais gráficos e alguns testes estatísticos para comprovar isso.
Trabalho concluído
Bem, acredito aqui que o trabalho de limpeza e formatação está concluído. Pude passar por diversos problemas oriundos de uma manutenção pobre dos dados. O conteúdo das páginas não é confiável e vê-se que a atualização é manual e sem verificações. No entanto, este é o trabalho de quem tem que garimpar dados na Internet, é necessário criar formas de verificação e validação das hipóteses assumidas. Ainda falta fazer a análise dos dados para tentar responder a pergunta de como o clima pode influenciar o desempenho dos corredores de rua, mas isso fica pra outro post. Por ora vou salvar estes dados em um arquivo csv para usar na continuação deste trabalho.