Avaliar o retorno de investimentos em diversos ativos pode levar a questões que vão além dos resultados individuais de cada ativo em um período de tempo. Até porque retornos passados não são justificativas para desempenho futuro. Existem muitas formas de visualização de ativos financeiros e já vimos algumas no post Indicadores de desempenho de ETFs. Hoje eu vou explorar o calendarmap que permite visualizar a dinâmica retornos de ativos financeiros ao longo do tempo, mas introduzindo que chamo de efeito calendário, pois os dados são agrupados em semanas e meses e isso permite a identificação de eventuais padrões sazonais.
O calendarmap é na prática um heatmap, só que eu divido as células em meses e dias de semana e a cor da célula é definida pela amplitude e direção do retorno do ativo, que varia em torno de zero e assim permite a criação de uma escala com cores distintas para retornos positivos e negativos. Dessa maneira, visualizo em um único gráfico o efeito de calendário nos retornos dos ativos e posso fazer isso com diversos ativos ao mesmo tempo.
Vou criar um heatmap utilizando o ggplot2 e transformar os dados de forma que seja simples o agrupamento dos meses e dias de semana. Novamente, vou trabalhar com dados de ETFs que são obtidos dos arquivos de cotações históricas da BM&FBovespa e eu carrego com facilidade utilizando o rbmfbovespa.
Além dos pacotes ggplot2 e rbmfbovespa vou carregar também dplyr, tidyr e xts que serão úteis no conjunto de transformações que terei que realizar para ter os dados em um formato adequado para a criação do gráfico.
library(ggplot2)
library(rbmfbovespa)
library(dplyr)
library(tidyr)
library(xts)
Carregando os dados de ETFs.
ch_2016 <- read_marketdata('datasets/COTAHIST_A2016.TXT', 'COTAHIST')
etfs <- ch_2016[[2]] %>% filter(especificacao == 'CI',
tipo_mercado == 10,
stringr::str_detect(nome_empresa, "^(BB ETF|CAIXAETF|ISHARE|IT NOW)"))
Vou fazer uma contagem da quantidade de dias que cada ETF apresentou valor para ter uma ideia da liquidez e utilizar isso para escolher quais ETFs vou colocar no gráfico.
etfs %>%
select(cod_negociacao, data_referencia, preco_ult) %>%
group_by(cod_negociacao) %>%
summarise(Count = n()) %>%
arrange(desc(Count)) %>%
formattable::formattable()
| cod_negociacao | Count |
|---|---|
| BOVA11 | 249 |
| DIVO11 | 249 |
| IVVB11 | 249 |
| PIBB11 | 249 |
| SMAL11 | 248 |
| ISUS11 | 246 |
| SPXI11 | 245 |
| GOVE11 | 242 |
| XBOV11 | 239 |
| BBSD11 | 238 |
| ECOO11 | 228 |
| BRAX11 | 225 |
| FIND11 | 223 |
| MATB11 | 153 |
| BOVV11 | 64 |
Bem, vou selecionar: DIVO11, GOVE11, BOVA11, PIBB11, SMAL11, ISUS11, IVVB11 e SPXI11.
etfs %>%
select(cod_negociacao, data_referencia, preco_ult) %>%
filter(cod_negociacao %in% c('DIVO11', 'GOVE11', 'BOVA11', 'PIBB11', 'SMAL11', 'ISUS11', 'IVVB11', 'SPXI11')) %>%
arrange(cod_negociacao, data_referencia) -> etfs_data
A variável etfs_data é um data.frame com três colunas: cod_negociacao, data_referencia e preco_ult. Este data.frame está no formato tidy, onde cada registro da tabela é referente a uma observação.
Note que eu ordeno por cod_negociacao e data_referencia, faço isso para que a tabela seja agrupada por ativos e que os dados dos ativos estejam ordenados pela data.
Agora vou separar cada ETF dessa tabela em séries temporais xts.
Em seguida junto todas as séries xts em um único objeto xts fazendo um merge das séries temporais para que finalmente eu calcule os retornos de todas as séries de uma vez.
Eu faço isso porque através do merge do xts eu preservo o índice entre as séries colocando NA nas datas das séries que não apresentam informação, dado que já levantei anteriormente que algumas séries possuem mais informações do que outras.
etfs_series <- lapply(split(etfs_data, etfs_data$cod_negociacao), function(x) {
xts(x$preco_ult, x$data_referencia)
})
etfs_series <- do.call(merge, etfs_series)
etfs_series <- PerformanceAnalytics::CalculateReturns(etfs_series, method = 'log')
Após a execução do trecho de código acima eu termino com a variável etfs_series que é um objeto xts com as séries temporais dos retornos das ETFs selecionadas.
Agora eu preciso voltar novamente ao formato tidy para criar o gráfico utilizando o ggplot2.
Dessa maneira, eu terei um data.frame onde cada registro terá cod_negociacao, data_referencia e retorno.
Para fazer isso eu executo as seguintes transformações em etfs_series:
- Transformo em um data.frame com
as.data.frameonde cada coluna é uma ETF - Crio a coluna
data_referenciaa partir doindexdeetfs_series, então além das colunas com as ETFs tenho também a nova coluna com a data de referência - Trasnformo o data.frame horizontal em um data.frame vertical onde os nomes das colunas formam a variável
cod_negociacaoe os valores formam a variávelretorno, ou seja, eu utilizo os nomes das colunas como labels para os valores que são os retornos. - Crio quatro novas colunas a partir de
data_referenciamesque é um factor com o mês abreviadodiaque é um inteiro com o dia do mêsdia_semanaque é um factor com o dia da semana abreviadosemana_mesque é a semana do mês ao qual o dia pertence
Precisei criar a função first_day_of_month_wday_adj para definir a semana do mês na qual a data de referência está.
É necessário fazer um ajuste no dia do mês (1 ... {28, 29, 30, 31}) pelo dia da semana (1 ... 7) para que um dia 7 que cai em uma segunda-feira fique na segunda semana e não na primeira.
Este ajuste é feito a partir de um descolcamento sobre os dias do mês de acordo com o dia da semana do primeiro dia do mês.
Se o primeiro dia do mês é um domingo o ajuste é zero, logo não há ajuste, se o primeiro dia da semana é uma segunda-feira, o ajuste é de 1 dia e dessa maneira o dia 7 do mês cai na segunda semana.
A regra segue para os demais dias da semana.
Ao fim chego ao data.frame etfs_returns sete colunas.
first_day_of_month_wday_adj <- function(dx) {
lubridate::day(dx) <- 1
lubridate::wday(dx) - 1
}
etfs_returns <- etfs_series %>%
as.data.frame() %>% # 1
mutate(data_referencia = index(etfs_series)) %>% # 2
gather(cod_negociacao, retorno, - data_referencia) %>% # 3
mutate(cod_negociacao = factor(cod_negociacao, levels = c('DIVO11', 'GOVE11', 'BOVA11', 'PIBB11', 'ISUS11', 'SMAL11', 'IVVB11', 'SPXI11'))) %>%
mutate(mes = factor(lubridate::month(data_referencia), labels = c("jan", "fev", "mar", "abr", "mai", "jun", "jul", "ago", "set", "out", "nov", "dez")),
dia = lubridate::day(data_referencia),
dia_semana = factor(lubridate::wday(data_referencia), labels = c("seg", "ter", "qua", "qui", "sex")),
semana_mes = ceiling((lubridate::day(data_referencia) + first_day_of_month_wday_adj(data_referencia)) / 7)) # 4
Agora vou chamar o ggplot2 para construir o calendarmap.
ggplot(etfs_returns, aes(y = dia_semana, x = semana_mes, fill = retorno)) +
geom_tile(colour = "grey50") +
facet_grid(cod_negociacao ~ mes) +
scale_fill_gradient2(low = "red", high = "darkgreen", midpoint = 0, na.value = "grey50") +
theme(axis.text = element_text(size = 10),
axis.title = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.ticks.y = element_blank(),
strip.text = element_text(size = 10),
legend.position = "none",
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank())
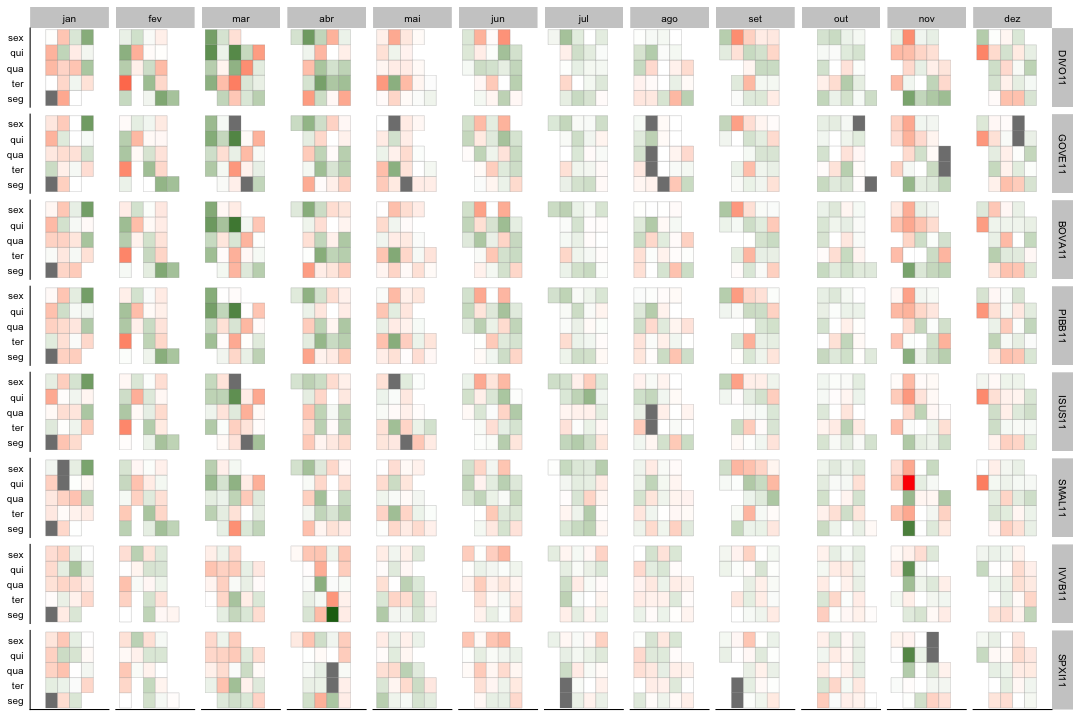
Bem, pessoalmente fiquei emocionado após concluir o gráfico acima, realmente, achei bom mesmo. É possível observar a dinâmica dos ativos ao longo do ano e é bem diferente de um gráfico de retornos (como no post Indicadores de desempenho de ETFs) onde a dinâmica dentro do calendário não fica evidente. Esse é um gráfico legal para se apresentar resultados de fundos de investimento, por exemplo.