Frequentemente eu consumo dados disponíveis na Internet para construir datasets em minhas análises. Em sua maioria são dados de mercado financeiro, que incluem:
- indicadores econômicos
- índices de inflação
- taxas de juros
- preços de ações
- preços de contratos futuros
- dados cadastrais de instrumentos financeiros negociados na BM&FBovespa
- taxas e preços de títulos públicos
- entre outros
Decidi apresentar formas automáticas de obter estes dados e este post é o primeiro da série webscraping.
Vou começar com IPCA porque venho trabalhando muito com ele recentemente de forma que criamos uma relação.
Eu capturo a série IPCA do site PortalBrasil no link
http://www.portalbrasil.net/ipca.htm.
Para fazer o webscraping eu usei o rvest.
No código abaixo eu leio a URL, seleciono a tabela com o IPCA mensal e converto em um data.frame.
library(rvest)
url <- 'http://www.portalbrasil.net/ipca.htm'
ipca_data <- read_html(url) %>%
html_nodes(xpath="//table") %>%
.[[6]] %>%
html_table(header=TRUE)
head(ipca_data)
## JAN FEV MAR ABR MAI JUN JUL AGO SET OUT NOV DEZ ACUMULADO\n NO ANO
## 1 1980 6,62 4,62 6,04 5,29 5,70 5,31 5,55 4,95 4,23 9,48 6,67 6,61 99,27%
## 2 1981 6,84 6,40 4,97 6,46 5,56 5,52 6,26 5,50 5,26 5,08 5,27 5,93 95,65%
## 3 1982 6,97 6,64 5,71 5,89 6,66 7,10 6,36 5,97 5,08 4,44 5,29 7,81 104,80%
## 4 1983 8,64 7,86 7,34 6,58 6,48 9,88 10,08 9,11 10,30 8,87 7,38 8,68 163,99%
## 5 1984 9,67 9,50 8,94 9,54 9,05 10,08 9,72 9,35 11,75 10,44 10,53 11,98 215,27%
## 6 1985 11,76 10,87 10,16 8,20 7,20 8,49 10,31 12,05 11,12 10,62 13,97 15,07 242,24%
Alguns pontos escondidos nas linhas de código acima:
- da página carregada a informação que eu queria estava na sexta tabela da página, como eu sabia disso? Não sou adivinho, imprimi tabala a tabela até chegar a que eu desejava.
- eu prefiro usar
xpathpara especificar os elementos de interesse. Nem sempre isso é possível, eventualmente o HTML não está bem formatado e os parsers não funcionam direito. Nestes casos bibliotecas como BeautifulSoup do python são mais eficazes. - eu utilizo a operação
.[[6]]após selecionar a tabela, porque? Ohtml_nodesretorna uma lista e tenho que extrair o sexto elemento da lista para trabalhar com ele. html_tableconverte a tabela em HTML em umdata.frameque eu chamo deipca_data.
A data.frame ipca_data tem alguns problemas de formato:
- os nomes das colunas devem ser formatados, em particular a primeira que está sem nome.
- as colunas estão como texto e devem ser convertidas para decimal
- a última coluna vai exigir um esforço adicional na conversão
Vamos limpar os dados extraindo apenas os números que interessam.
Eu uso uma expressão regular onde especifico um decimal separado (ou não) por vírgula e capturo em um grupo.
Em seguida eu troco , por . e depois converto para numeric.
Note que eu uso suppressWarnings porque alguns valores não são convertidos e geram NA e eu não quero as mensagens de aviso na saída.
.d <- dim(ipca_data)
.data <- lapply(ipca_data[,1:.d[2]], function (x) {
x <- stringr::str_replace(x, '^[^0-9]*(\\d+(\\.\\d+)?(,\\d+)?)[^0-9]*$', '\\1')
x <- stringr::str_replace(x, '\\.', '')
x <- stringr::str_replace(x, ',', '.')
x <- suppressWarnings(as.numeric(x))
x
})
.data é uma lista com as colunas do data.frame contendo todos os números formatados.
Agora vou converte-lo novamente em um data.frame.
.data <- do.call(data.frame, .data)
Ainda é necessário corrigir os nomes. Vou renomear todas as colunas, pois prefiro trabalhar com os meses em formato numérico e separar a primeira coluna do ano e a última da inflação acumulada no ano.
colnames(.data) <- c('ano', 1:12, 'acumulado')
.data
## ano 1 2 3 4 5 6 7 8 9 10 11 12 acumulado
## 1 1980 6.62 4.62 6.04 5.29 5.70 5.31 5.55 4.95 4.23 9.48 6.67 6.61 99.27
## 2 1981 6.84 6.40 4.97 6.46 5.56 5.52 6.26 5.50 5.26 5.08 5.27 5.93 95.65
## 3 1982 6.97 6.64 5.71 5.89 6.66 7.10 6.36 5.97 5.08 4.44 5.29 7.81 104.80
## 4 1983 8.64 7.86 7.34 6.58 6.48 9.88 10.08 9.11 10.30 8.87 7.38 8.68 163.99
## 5 1984 9.67 9.50 8.94 9.54 9.05 10.08 9.72 9.35 11.75 10.44 10.53 11.98 215.27
## 6 1985 11.76 10.87 10.16 8.20 7.20 8.49 10.31 12.05 11.12 10.62 13.97 15.07 242.24
## 7 1986 14.37 12.72 4.77 0.78 1.40 1.27 1.71 3.55 1.72 1.90 5.45 11.65 79.65
## 8 1987 13.21 12.64 16.37 19.10 21.45 19.71 9.21 4.87 7.78 11.22 15.08 14.15 363.41
## 9 1988 18.89 15.70 17.60 19.29 17.42 22.00 21.91 21.59 27.45 25.62 27.94 28.70 980.22
## 10 1989 37.49 16.78 6.82 8.33 17.92 28.65 27.74 33.71 37.56 39.77 47.82 51.50 1972.91
## 11 1990 67.55 75.73 82.39 15.52 7.59 11.75 12.92 12.88 14.41 14.36 16.81 18.44 1620.96
## 12 1991 20.75 20.72 11.92 4.99 7.43 11.19 12.41 15.63 15.63 20.23 25.21 23.71 472.69
## 13 1992 25.94 24.32 21.40 19.93 24.86 20.21 21.83 22.14 24.63 25.24 22.49 25.24 1119.09
## 14 1993 30.35 24.98 27.26 27.75 27.69 30.07 30.72 32.96 35.69 33.92 35.56 36.84 2477.15
## 15 1994 41.31 40.27 42.75 42.68 44.03 47.43 6.84 1.86 1.53 2.62 2.81 1.71 916.43
## 16 1995 1.70 1.02 1.55 2.43 2.67 2.26 2.36 0.99 0.99 1.41 1.47 1.56 22.41
## 17 1996 1.34 1.03 0.35 1.26 1.22 1.19 1.11 0.44 0.15 0.30 0.32 0.47 9.56
## 18 1997 1.18 0.50 0.51 0.88 0.41 0.54 0.22 0.02 0.06 0.23 0.17 0.43 5.22
## 19 1998 0.71 0.46 0.34 0.24 0.50 0.02 0.12 0.51 0.22 0.02 0.12 0.33 1.66
## 20 1999 0.70 1.05 1.10 0.56 0.30 0.19 1.09 0.56 0.31 1.19 0.95 0.60 8.94
## 21 2000 0.62 0.13 0.22 0.42 0.01 0.23 1.61 1.31 0.23 0.14 0.32 0.59 5.97
## 22 2001 0.57 0.46 0.38 0.58 0.41 0.52 1.33 0.70 0.28 0.83 0.71 0.65 7.67
## 23 2002 0.52 0.36 0.60 0.80 0.21 0.42 1.19 0.65 0.72 1.31 3.02 2.10 12.53
## 24 2003 2.25 1.57 1.23 0.97 0.61 0.15 0.20 0.34 0.78 0.29 0.34 0.52 9.30
## 25 2004 0.76 0.61 0.47 0.37 0.51 0.71 0.91 0.69 0.33 0.44 0.69 0.86 7.60
## 26 2005 0.58 0.59 0.61 0.87 0.49 0.02 0.25 0.17 0.35 0.75 0.55 0.36 5.69
## 27 2006 0.59 0.41 0.43 0.21 0.10 0.21 0.19 0.05 0.21 0.33 0.31 0.48 3.14
## 28 2007 0.44 0.44 0.37 0.25 0.28 0.28 0.24 0.47 0.18 0.30 0.38 0.74 4.45
## 29 2008 0.54 0.49 0.48 0.55 0.79 0.74 0.53 0.28 0.26 0.45 0.36 0.28 5.90
## 30 2009 0.48 0.55 0.20 0.48 0.47 0.36 0.24 0.15 0.24 0.28 0.41 0.37 4.31
## 31 2010 0.75 0.78 0.52 0.57 0.43 0.00 0.01 0.04 0.45 0.75 0.83 0.63 5.90
## 32 2011 0.83 0.80 0.79 0.77 0.47 0.15 0.16 0.37 0.53 0.43 0.52 0.50 6.50
## 33 2012 0.56 0.45 0.21 0.64 0.36 0.08 0.43 0.41 0.57 0.59 0.60 0.79 5.83
## 34 2013 0.86 0.60 0.47 0.55 0.37 0.26 0.03 0.24 0.35 0.57 0.54 0.92 5.91
## 35 2014 0.55 0.69 0.92 0.67 0.46 0.40 0.01 0.25 0.57 0.42 0.51 0.78 6.40
## 36 2015 1.24 1.22 1.32 0.71 0.74 0.79 0.62 0.22 0.54 0.82 1.01 0.96 10.67
## 37 2016 1.27 0.90 0.43 0.61 0.78 0.35 0.52 0.44 0.08 0.26 0.18 0.30 6.28
## 38 2017 0.38 0.33 0.25 0.14 0.31 0.23 0.24 0.19 0.16 0.42 NA NA 2.21
Eu diria que aqui termina o trabalho de webscraping, no entanto, os dados não estão em um formato adequado para trabalhar.
Um formato que eu considero interessante é o de uma série temporal onde cada inflação é representada por um par data (mês e ano) e valor.
Neste contexto a coluna acumulado é ignorada e por isso vamos começar removendo-a
.data <- subset(.data, select=-acumulado)
Agora vou transformar os dados.
.data <- within(reshape2::melt(.data, id="ano"), {
variable <- as.numeric(variable)
mes <- as.Date(paste(ano, variable, '01', sep='-'))
rm(ano, variable)
})
Esse comando faz diversas coisas e retorna um data.frame com a pattern data-valor, no entando as datas estão fora de ordem.
Para colocar os dados em ordem cronológica eu vou criar um objeto de série temporal.
Gosto do pacote xts que cria objetos de séries de tempo com avançadas funcionalidades de indexação.
library(xts)
ipca <- with(.data, xts(value, mes))
names(ipca) <- 'IPCA'
plot(ipca, main='IPCA')
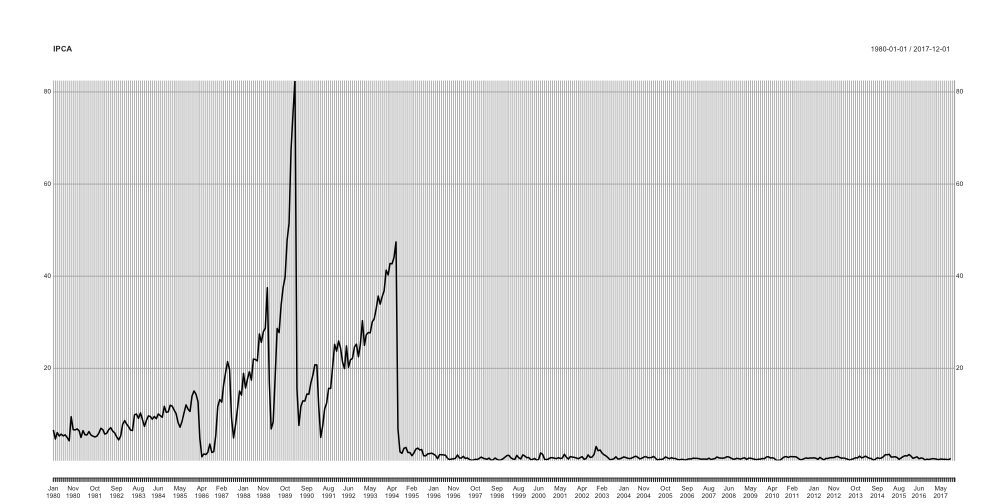
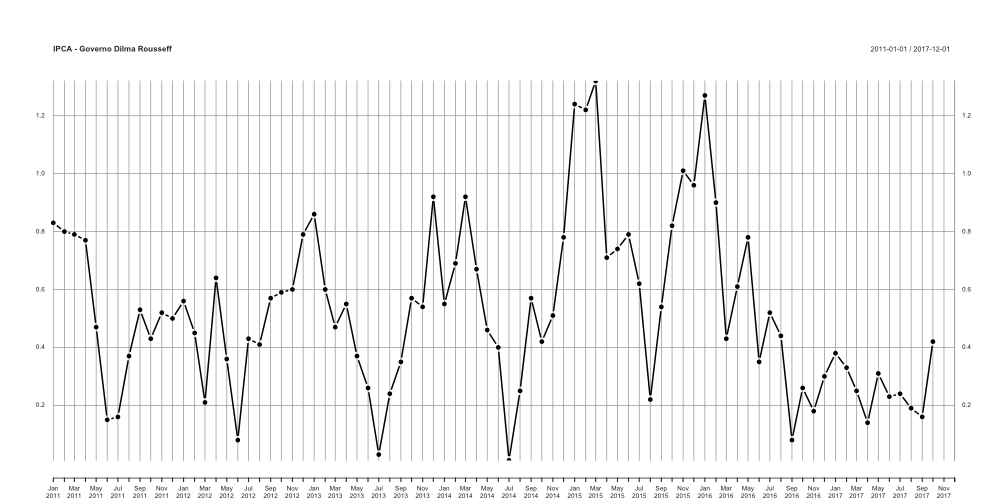
A inflação no governo Dilma Rousseff (2011-).
plot(ipca['2011/'], type='b', pch=19, main='IPCA - Governo Dilma Rousseff')
Conclusão
Vimos como capturar a série temporal do IPCA do site PortalBrasil. Há outras formas de obter a série do IPCA, para citar 2 temos o webservice do Banco Central e o Quandl. No entanto a extração apresentada aqui trabalha dados brutos, o que pra mim é melhor porque eu tomo as decisões sobre a manipulação e interpretação dos dados. Além disso utilizo apenas HTTP, preciso apenas que o site esteja no ar disponibilizando páginas estáticas, as outras alternativas são serviços onde é necessário uma API para obter os dados.